工廠直供 個性數碼相機包與專業攝像服務全解析
隨著數碼攝影的普及,相機不僅是記錄工具,更成為彰顯個性的時尚配件。工廠直接供應的精美個性數碼相機包,正以其多樣設計、實用功能與高性價比,贏得眾多攝影愛好者的青睞。
一、個性數碼相機包:不止于保護
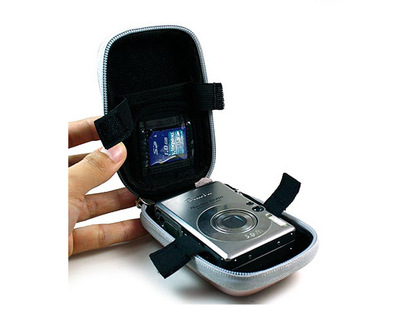
工廠供應的數碼相機包,涵蓋廣泛品類,從簡約內膽包到多功能雙肩攝影包,滿足不同場景需求。EVA材質相機包因其輕便、耐磨且具備一定抗震性,成為熱門選擇。這類包體通常設計有加厚防震隔層,能有效保護佳能、尼康等品牌的相機與鏡頭免受碰撞。
“個性”是核心賣點。廠家提供豐富的自定義選項:
- 外觀設計:多種色彩、圖案(如迷彩、純色、印花)及材質(如尼龍、帆布、仿皮革)可選。
- 結構功能:可調節隔板、側邊快取開口、防水涂層、前袋收納存儲卡與電池等。
- 款式多樣:包括單肩包、斜挎包、背包、腰包等,適應旅行、街拍、戶外等不同攝影風格。
圖片展示的18款EVA相機包,通常體現了這種多樣性,從緊湊型卡片機包到可容納一機多鏡的專業包,視覺上直觀呈現其設計與容量。
二、匹配專業需求:佳能、尼康相機包專項優化
針對佳能、尼康等主流品牌相機型號,工廠生產的相機包常進行專項優化。隔層尺寸精準匹配相機機身與常見鏡頭(如標準變焦、定焦鏡頭),確保設備固定穩固,避免晃動。部分高端系列還會為特定型號(如佳能EOS R5、尼康Z7)設計專屬模具,實現“定制化”保護。
三、EVA材質的優勢與適用場景
EVA(乙烯-醋酸乙烯酯共聚物)是一種輕質彈性材料,用于相機包具有明顯優點:
- 輕量化:相比傳統硬質包,大幅減輕攜帶負擔。
- 抗震性:吸收輕微沖擊,保護精密設備。
- 防水防潮:基礎防護應對日常小雨或潮濕環境。
- 成本效益:工廠直供減少中間環節,價格更具競爭力。
它尤其適合日常通勤、短途旅行及非極端戶外拍攝,平衡了保護性與便攜性。
四、延伸服務:專業攝像服務
許多工廠或關聯供應商不僅提供產品,還整合了專業攝像服務,形成“裝備+服務”的一體化解決方案。這類服務可能包括:
- 活動跟拍:如婚禮、會議、慶典的現場攝影與錄像。
- 商業拍攝:產品靜物、企業宣傳片、網店圖片拍攝等。
- 技術咨詢:為客戶推薦適合其設備的包具或攝影配件。
- 定制印刷:為企業或團隊批量定制帶有LOGO的相機包,提升品牌形象。
選擇工廠直供時,消費者應注意核實廠家資質、材料環保標準及服務條款,確保產品質量與售后保障。
從個性化EVA相機包到專業攝像服務,工廠直供模式為攝影愛好者與專業人士提供了高性價比且靈活的選擇。無論是保護心愛的相機,還是尋求全面的影像解決方案,明確自身需求并選擇可靠供應商,都能讓攝影之旅更加安心與精彩。
如若轉載,請注明出處:http://www.zzscsxxtsg.cn/product/79.html
更新時間:2026-05-27 11:54:21